
DevOpsDays is a technical conferences covering topics of software development, IT infrastructure operations, and the intersection between them. Topics often include automation, testing, security, and organizational culture.
It is a place where people and companies come together and share their experiences on how they handled different challenges related to DevOps.
This is my first time attending DevOpsDays India conference and I took lot of notes. Here are the digitized version of my notes of the different talks as I have written down/remember them.

Day 1
Keynote by Nathen Harvey
Nathen Harvey (@NathenHarvey) is the VP of Community Development at Chef Software. If you want to learn Chef, head out to learn.chef.io for a nice series of tutorials and courses.
- We engineers are
- Not tied down to legacy, technical debt.
- Not spin up cloud servers.
- Not just build systems.
- Your primary job is to “Delight your customers”.
- Build ➡ Scale ➡ Service your customers.
- Code / Chef / ansible / whatever you use, always put it in a VCS.
- Writing Tests (good) vs Nagios Alerts (bad).
- Writing any test cases is good.
- Writing NO test cases is bad.
- Test cases will evolve as you evolve. So doesn’t matter if they are not comprehensive.
- Always do Static Analysis
- cookstyle - tests the style guide for ruby scripts.
- foodcritic - tests the style guide for chef scripts.
- Integration Testing
- Start a Virtual Machine.
- Get your code onto it.
- Test.
- FOUR Eye Rule
- Always have four eyes look at the code before pushing to production.
- Code review is an important part of the testing process.
- Source Repo ➡ Artifact ➡ Artifact Repo.
- Information Security
- 81% IT Professionals think infosec team inhibits speed of deploy/production.
- 77% Infosec Professionals also think so.
- For collaboration, make things visible.
- make it clear where our constraints & bottlenecks are.
- Software Success Metrics:
- Speed
- Efficiency
- Risk
- Detect Failures Early on.
- Continuous Improvement
- Learn Actively.
- Share information - metrics/reports.
- Align incentives & Objects of all teams.
- Post Mortem - Always ask these 2 questions:
- How could we have detected this sooner?
- How could we avoid it in the future?
- Know your customer.
- Make work visible.
- Measure Progress.
- Participate in the community.
My important takeaway from this talk is “Delight your Customer”. The only reason you are being hired to do the job you do is to solve your customer’s problems.
As engineers/developers we are able to create something new. But whatever we create, if it doesn’t solve a customer’s pain point, it is of no use.
Managing your Kubernetes cluster using BOSH
Ronak Banka (@ronakbanka) is working with Rakuten
Principle at Rakuten:
- Always improve. Always Advance.
- Passionately professional.
- Hypothesise -> Practice -> Validate -> Shikunika.
- Maximise Customer Satisfaction.
- Speed! Speed! Speed!
Pain points of growing automation tools:
- High availability
- Scaling
- Self healing infra
- Rolling upgrades
- Vendor lock-in
Using BOSH, release engineering, deployment, lifecycle management, etc., becomes easier.
Moving 65000 Microsofties to Devops on the Public Cloud
Moving to One Engineering System
By Sam Guckenheimer (@SamGuckenheimer) (Visual Studio Team Services)
- In Microsoft before 2011s, Each team had their own Enginnering, own code base, No dependencies amongst teams.
- Satya Nadella introduced One Engineering System. More open.
- Productivity is more important any other feature.
- PR ➡ Code Review ➡ Test cases ➡ Security Test ➡ Merge to master ➡ Continuous Integration.
- Runs 60237 tests in 6:39 minutes.
- There is a limit of 8 min for running test cases. Previously was 10 min.
- 12 hours limit to do code review. Else the PR expires. Dev has to resubmit a new PR/Code review.
- Git Virtual File System
- Linux Kernel 0.6GB
- VSTS 3GB
- Windows 270GB
- Overall 300x improvement from cloning to commiting.
- Metrics to track
- Live Site Health
- Velocity
- Engineering
- Usage
- Publish Root Cause Analysis (RCA) in a blog for more serious issues - more transparency.
- Assigning to teams
- Each team lead has 2 mins to pitch about his team and why people need to join their team.
- developers can choose 3 teams they are interested to work in and their priority.
- Match developers to teams based on choice and availability.
- > 90% match rate.
- Sprints
- Don’t think more than 3 sprints ahead.
- too much uncertainty and stale features.

My takeaway: Even a huge organization like Microsoft can be made to follow best practices. There is hope for the small startups that do stuff adhoc.
Devops at scale is a Hard problem
By Kishore Jalleda (@KishoreJalleda), worked in IMVU, Zynga, currently a Senior Director at Yahoo!
- Democratize Innovation
- Do not have pockets of Innovation. Eg: Innovation Lab Division.
- You can’t time and control innovation within a specific team.
- No permissions required to ship features to 1% of users.
- Move fast. Have very high velocity.
- But Privacy & Security is a non-negotiable.
- You wrote it; you own it.
- You wrote it; you run it.
- Alerting
- Alert ➡ team a ➡ team b ➡ team c ➡ dev.
- Alert ➡ dev. (much better)
- Ideal: <2 alerts/shift, so that RCAs are possible.
- Saying No is hard, but powerful.
- Logs are better than Emails for alerts.
- Commits go to production:
- With human involvement.
- Without human involvement. (better)
- Needs TDD.
- Takes time. Lot of opposition. Not every one buys in.
- Have very very high velocity
- Test coverage will never be 100% - but its ok. Just like there are bugs in softwares, it doesn’t matter.
- Automation
- Don’t reward bad behaviour.
- Don’t allow developers to NOT automate their stuff. Restarting a server every day at 3am is bad behaviour.
- Automation allows you to do “Higher value work”.
- What do you want to do? Restart servers? or write production code?
- Stop saying things that don’t matter.
- Public cloud vs private data centers:
- Go for hybrid approach, buy or build based on time and use case
- If you do things that are not aligned to the rest of the company : “break the rules but break them in broad daylight”.
- Build new apps with cloud in mind.
- Incentivise teams to automate.
- Reward good behaviour.
- Move fast to stay relevant.
- Don’t aim for 100% compliance.
- It is the process that matters.
My takeaway: You can’t get 100% compliance from day 1. Getting everyone on board to follow automation, test cases, code review, CI/CD is hard. Eventually people (if they are smart) will get there.
Also, the main incentive to automate your stuff is that you can go ahead and work on much bigger and better challenges. Solving problems for the next 1 Billion users will be more interesting than restarting servers any day.
Lessons Learned from building a serverless distributes & batch data architecture
- Always return from your lambda functions. Else it is an error and AWS retries that function again.
- Don’t use server to monitor serverless.
- Serverless Distributed system ➡ has to be self healing.
- when processing hundreds of servers, debugging a lost file is hard.
- have proper load balancing.
- Don’t try micro optimizations with distributed systems.
- Check out Distributed Tracing:
My takeaway: Tools for Distributed Tracing looks interesting. I do want to begin using these so that it will be easier to debug the different microservices.
Day 1 ended with a few lightning talks and then a workshop on Kubernetes.
Day 2
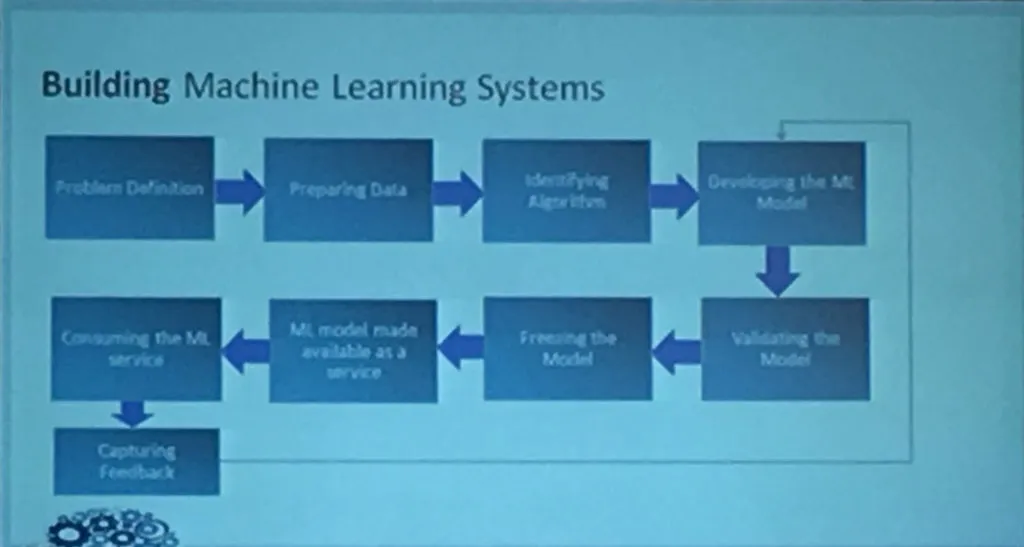
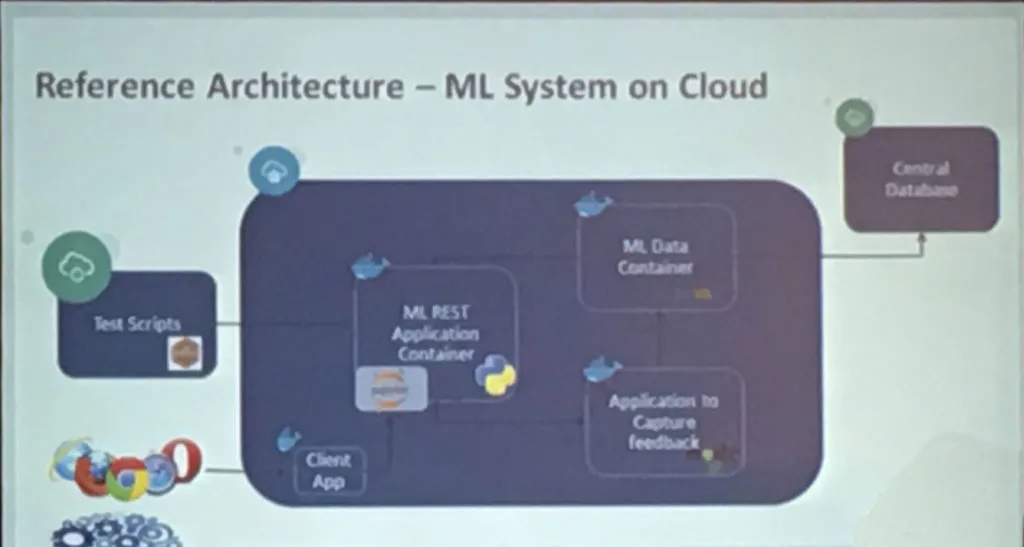
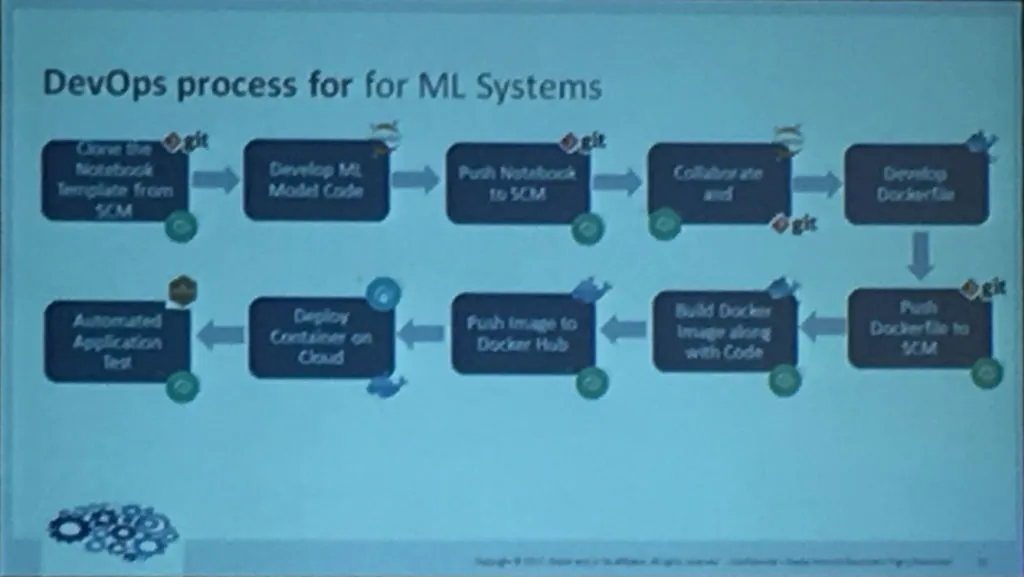
Building Thinking System - Machine Learning Dockerized
By Abhinav Shroff - (@abhinavshroff)
- Building Applications Smarter - with data.
- ML Systems require feedback - This requires the right Devops Strategy and tooling.
- Language
- Python
- R
- Devtools
- Eclipse
- Jupyter
- RStudio
- Why Containerize?
- Tuning
- Bundled
- Self-contained
- Clustering
- Defined Interface
- Cloud Microservice
- Container Orchestration Options
- Docker Swarm
- Kubernetes
- Apache Mesos
- (or)
- Container Deployment Cloud (Oracle Developer Cloud Service)
- Microservices
- Jupyter Kernel Gateway
- Create a REST service in your jupyter notebook.
Mario Star Power Your Infrastructure: Infrastructure testing a la Devops with Inspec
By Hannah Madely (@DJPajamaPantz) & Victoria Jeffrey (@vickkoala) from Chef Software.
As I am not a Chef/related software kind of guy (Ansible FTW), I didn’t pay too much attention on this talk. But they had the best slides in the entire conference. Go Mario Go.
- Inspec Test runner over
- SSH
- WinRM
- Docker
- Inspec Shell
- Shorter feedback loop is very important
- Ready to use profiles available on
- Github
- Supermarket
Reliability at Scale
By Praveen Shukla (@_praveenshukla) from GoJek Engineering
Reliability translates to Business Profits. But pitching this to business people is hard. This is the story of how the GoJek Engineering team made their systems reliable at scale.
- 100 instances to 8000 instances
- 1 Million (Internal) Transactions per second
- Reliability
- Uptime - 4 nines
- MTBF - Uptime/breakdown
- Failure per year (AFR)
- QoS
- SLA - 2ms response vs 2s response, which is reliable?
- To define reliability, define failure first.
- Failure: Systems operating outside specified parameters
- Failure according to Business: Users are complaining
- 2015
- 4 products
- 10 microservices
- 100 instances
- 50+ tech people
- velocity vs stability
- 2017
- 18 products
- 250+ microservices
- 8000+ instances
- 3 data centers
- AWS, GCE, Own datacenter
- 350+ tech people
- Issues
- CI/CD
- Jenkins
- Pipeline access management.
- custom deployment - have to goto the devops/SRE team.
- DSL repository management. code and CI lives in two diff repos.
- No branch based deployment
- Configuration Management
- Create a Cookbook for each microservice.
- 350+ cookbooks.
- Alerting & Monitoring
- Alerts getting lost.
- Not getting alerts to the right person.
- too many pagers to too many people.
- who is responsible to take action on an alert?
- Solutions
- CI/CD
- Configuration Management
- Use 4 languages
- ruby
- golang
- clojure
- jruby
- Create a master cookbook for each language
- 4 cookbooks instead of 350
- Use 4 languages
- Alerting & Monitoring
- Smart Alert Router
- Each product belongs to 1 Group
- Each group has many microservices
- Each microservice runs on multiple servers
- Each member belongs to multiple groups
- When an alert happens on a server, the corresponding group alone gets the alert
- Configuring an alert
- create an yaml file
- push it to repo
- CI configures the alert from the yaml file
- Smart Alert Router
- Reliability and dependency
- 1 service: R:99%
- 1 ⬅ 3 services: R: 97%
- 1 ⬅ 3 ⬅ 3 services: R:88%
- Fail Fast.
- Use circuit breakers.
- 99.99% uptime for 30 microservices gives only 99.7% uptime for the entire system.
- 0.3% of 1 Billion requests ➡ 3 Million requests failure
- 2+ hours of downtime every month
- Queueing Delay
- Scaling up can’t solve everytime
- DDOS will kill it
- Instead throttle your system
- Reliability is an iterative process
Move fast with Stable build Infrastructure
By Sanchit Bahal (@sanchit_bahal) from Thoughtworks
Context:
Thoughtworks was asked to build a mobile app for an Airline Baggage system.
They usually use Git + GoCD for CI/CD. But the client didn’t want a public cloud. So build machines were in house - mix of Macs and linux VMs.
They began experiencing long wait times for the builds, sometimes ~1.5 days.
This causes a delayed feedback for the developer and by the time the build result is generated, the developer has moved ahead. This began causing mostly Red Builds and finally developers stopped looking at the builds.
Journey:
- Automate the provisioning
- Using Ansible.
- installation of xcode, android sdk.
- use local file server for heavy downloads.
- Pre-baked golden image
- OSX + Ansible ➡ image.
- Use deploy studio.
- New machine takes 30 mins instead of 2 days.
- Homogenous Build agents
- all machines ➡ all build types.
- better load balanced.
- better work allocation.
- resilience.
- 1 Build agent per machine
- Simplified set up.
- easier allocation of work load.
- Emulator
- Geny motion ➡ Android Emulator.
- Genymotion was getting stuck sometimes. Indeterministic.
- Spin up & spin down of Android Emulator on every test suite.
- Run in headless mode.
- save on licensing code. $30000/year for 80 people.
- Android emulators allow to start in a clean slate and end in a clean slate.
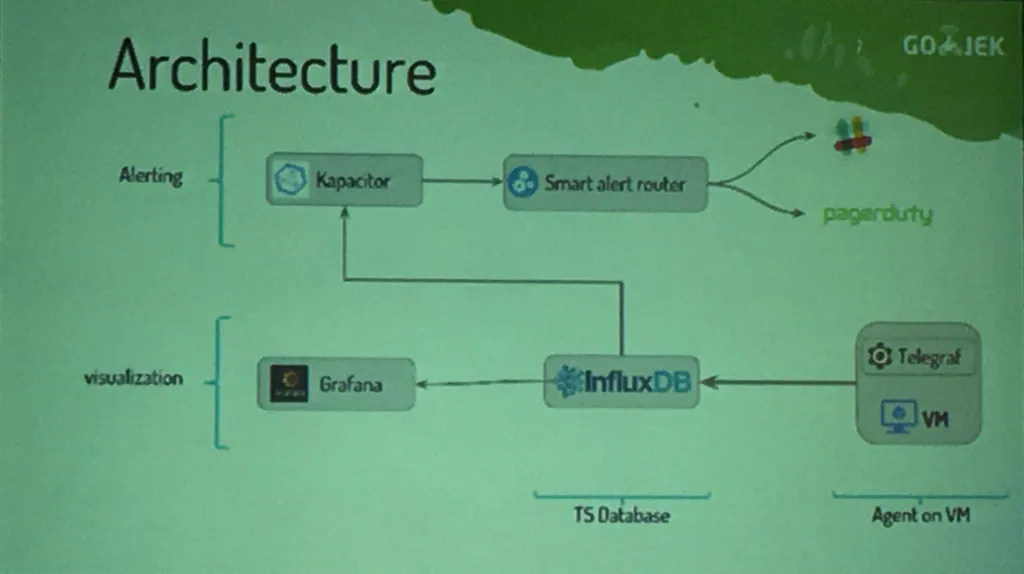
- Devops Analytics
- Measure Improvements.
- Continuous Monitoring.
- Actionable Insights.
- Telegraf + influxdb + grafana.
- Dashboard
- Build wait time - time to assign a build agent to a scheduled job.
- Deploy ready build - time from commit to build ready for QA.
- build machines health - load, CPU, memory, disk, etc.
- Outcomes
- Machine provisioning time: 2 days ➡ < 30 mins.
- Build wait time: 6 hours ➡ < 10secs.
- Stable, robust, resilient build infrastructure.
- faster feedback cycle ➡ more commits/day.
- better developer productivity.
My takeaway: Developer productivity is very important and quicker feedback loop allows you to commit code faster.
Prometheus 2.0
This was a lightning talk by Goutham (@putadent) a GSoC student who was working on Prometheus. He was talking about the lower memory usage and other improvements in v2.0.
It is still in beta, but since Prometheus pulls metrics, Have both 1.x and 2.0 on your servers. Switch versions when it becomes stable.
Prometheus has been on my radar for quite some time and I think I should play around with it to see how it works and where I can plug it in.
Finishing Keynote: Sailing through your careers with the community
By Neependra (@neependra) - CloudYuga
Community! Community! Community!
- What can community do to your career
- Satisfaction.
- Get visibility.
- Get the job you love.
- Start something of your own.
- What stops us from being part of community
- Time commitment.
- Company culture.
- FEAR.
- Comfort zone.
- Build a brand for yourself.
That was the end of the DevOpsDays 2017 Conference. Overall most of the talks were pretty good and I did have at least one key takeaway from each talk. From the different talks, it shows that lot of people have struggled to bring about the change in their companies to bring the DevOps mindset of automation, TDD, code reviews, etc.
I also have been trying to do it in Mad Street Den for some time, but like others have noted, the change is slow. If we keep sticking to it, the advantages we get out of it would be worth the journey.
If there are any corrections to the notes, please leave a comment below. When I get the links to the slides/video, I will update this.